A Practical Guide to Feature Selection Using Sklearn
Sep 26, 2022
When building a predictive model, we often have many features or variable in our dataset that can be used to train our model. However, just because the feature exists in our dataset does not mean that it is relevant for our model or that we should use it.
So how do we know which features to use in our model?
This is where feature selection comes in. Feature selection is simply a process that reduces the number of input variables, in order to keep only the most important ones.
There is an advantage in reducing the number of input features, as it simplifies the model, reduces the computation cost, and it can also improve the model’s performance.
Now, how do we decide which feature is important? What does it mean for a feature to be important?
There is no clear answer for that, so we need to experiment with different methods and see which gives the best results.
In this article, we are going to explore and implement three different feature selection methods:
- variance threshold
- K best features
- recursive feature elimination (RFE)
Each method has its own definition of importance, and we will see how it impacts the performance of our model. We will implement each method using Python and scikit-learn. At any point, you can check the full source code on GitHub.
Don’t miss out on future articles! Subscribe to my list to get new content straight to your inbox!
Let’s get started!
Getting the data
The first natural step is to get the data that we will use throughout this tutorial.
Here, we use the wine dataset available on sklearn. The dataset contains 178 rows with 13 features and a target containing three unique categories. This is therefore a classification task.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
wine_data = load_wine()
wine_df = pd.DataFrame(
data=wine_data.data,
columns=wine_data.feature_names)
wine_df['target'] = wine_data.target

From the image above, we can see that we have difference wine characteristics that will help us categorize it.
We can optionally plot the box plot of a few features to see if there is overlapping.
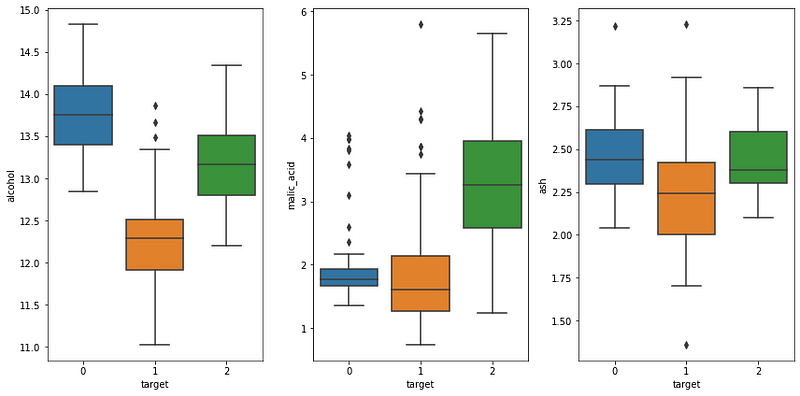
From the picture above, we can see that alcohol does not overlap much between each category, while there is clearly some overlapping for the other two features.
Ideally, we would not have any overlapping, which would allow us to classify each wine perfectly, but that is not the case here.
We won’t do more exploration here in order to focus on feature selection techniques. Thus, let’s move on to splitting our data into a training and test set before diving into feature selection.
Splitting the data
Before implementing feature selection techniques, we first split our data into a training and test set.
That way, we have fixed starting points and a fixed test set so that we can compare the impact of each feature selection method on the model’s performance.
from sklearn.model_selection import train_test_split
X = wine_df.drop(['target'], axis=1)
y = wine_df['target']
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.3,
shuffle=True,
stratify=y,
random_state=42)
With this split, we have 124 samples for the training set, and 54 samples for the test set. Note the use of stratify, which ensures that both the train and test sets contain the same proportion of the target class.
We are now ready to test and implement different feature selection methods!
Selecting the best features
We now dive into the feature selection methods. As mentioned above we will try three different methods and see how it impacts the model’s performance.
To make this experiment robust, we will use a simple decision tree classifier.
Variance threshold
The first method we will explore is the variance threshold. This is, of course, based on the variance, which is a measure of dispersion. In other words, it measures how far a set of number is spread out from their average value.
For example, the variance of [1, 1, 1, 1, 1] is 0, because each number is equal to their average value. Therefore, they do not spread out from their mean value.
Variance threshold then simply removes any feature with a variance that is below a given threshold.
We can see how this is useful to remove features with a variance close to 0, because this means that the values are constant or vary only slightly across all samples of the dataset. Therefore, they do not have any predictive power.
Thus, let’s compare the variance of each feature in our training set.
X_train_v1 = X_train.copy()
X_train_v1.var(axis=0)

In the figure above, we can see the variance for each of the features of the training set. However, we cannot define a variance threshold just yet, because our data does not have the same scale, and so the variance is not on the same scale either.
Data on a larger scale can have a higher variance than features on a smaller scale, even if their distribution is similar.
Thus, it is important to first scale our data before defining a threshold. Here, we normalize the data and then calculate the variance.
from sklearn.preprocessing import Normalizer
norm = Normalizer().fit(X_train_v1)
norm_X_train = norm.transform(X_train_v1)
norm_X_train.var(axis=0)

From the figure above, we can now see the variance of each scaled feature. While the variance is very small for all, some feature have incredibly small variance, with power to -8 and to -7.
Thus, let’s set our threshold to 1e-6. Any feature with a variance below that threshold will be removed.
from sklearn.feature_selection import VarianceThreshold
selector = VarianceThreshold(threshold = 1e-6)
selected_features = selector.fit_transform(norm_X_train)
selected_features.shape
Here, two features are removed, namely hue and nonflavanoid_phenols.
We can now see how a decision tree classifier performs when using all the features available, and we remove the two features mentioned above.
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import f1_score
dt = DecisionTreeClassifier(random_state=42)
#Classifier with all features
dt.fit(X_train, y_train)
preds = dt.predict(X_test)
f1_score_all = round(f1_score(y_test, preds, average='weighted'),3)
# Classifier with selected features with variance threshold
X_train_sel = X_train.drop(['hue', 'nonflavanoid_phenols'], axis=1)
X_test_sel = X_test.drop(['hue', 'nonflavanoid_phenols'], axis=1)
dt.fit(X_train_sel, y_train)
preds_sel = dt.predict(X_test_sel)
f1_score_sel = round(f1_score(y_test, preds_sel, average='weighted'), 3)
Printing the F1-score for both models gives 0.963. Thus, removing two features did not improve the model, but we do achieve the same performance.
Therefore, a simpler model with fewer features achieved the same result as using all features, which is a good sign.
Now, using variance threshold is somewhat simple, and setting the threshold is somewhat arbitrary.
With the next method, we can easily find the optimal number of variables to keep while deciding the selection criteria.
K best features
Here, we use a method that gives more flexibility in evaluating the importance of a feature.
The algorithm is simple: we simply provide a method of calculating the importance of a feature and the number of features we want to use, denoted as k. Then, the algorithm simply returns the top k features.
The main advantage of this method is that we are free to choose among a variety of ways to compute the importance of a feature. For example, we can use the chi squared test to quantify the independence of a feature to a the target. The higher the score, the higher the dependency between the feature and the target, and so the higher the importance of that feature.
Other methods can be used, such as computing the mutual information, using the False Positive Rate test, or calculating the F-statistic for a regression task.
Now, we still have the challenge of determining how many variables should be selected for the model. Here, since we are working with only 13 features in total, let’s try using one to all features and see which configuration gives us the best results.
Here, we use the chi squared test, as we are working with a classification task.
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
X_train_v2, X_test_v2, y_train_v2, y_test_v2 = X_train.copy(), X_test.copy(), y_train.copy(), y_test.copy()
f1_score_list = []
for k in range(1, 14):
selector = SelectKBest(chi2, k=k)
selector.fit(X_train_v2, y_train_v2)
sel_X_train_v2 = selector.transform(X_train_v2)
sel_X_test_v2 = selector.transform(X_test_v2)
dt.fit(sel_X_train_v2, y_train_v2)
kbest_preds = dt.predict(sel_X_test_v2)
f1_score_kbest = round(f1_score(y_test, kbest_preds, average='weighted'), 3)
f1_score_list.append(f1_score_kbest)
print(f1_score_list)
We can now plot the F1-score for each number of variables used in the model:
fig, ax = plt.subplots(figsize=(12, 6))
x = ['1','2','3','4','5','6','7','8','9','10','11','12','13']
y = f1_score_list
ax.bar(x, y, width=0.4)
ax.set_xlabel('Number of features (selected using chi2 test)')
ax.set_ylabel('F1-Score (weighted)')
ax.set_ylim(0, 1.2)
for index, value in enumerate(y):
plt.text(x=index, y=value + 0.05, s=str(value), ha='center')
plt.tight_layout()
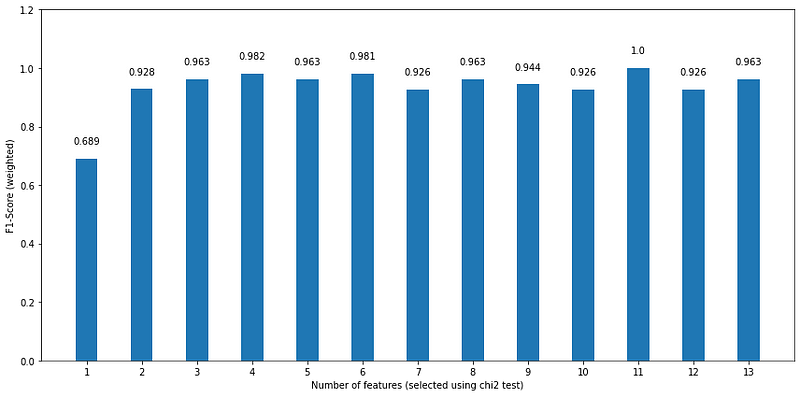
Looking at the figure above, we see that using only the most important feature, according to the chi squared test, gives us the worst performance, while using the top 11 features results in a perfect F1-score. However, let’s also notice that using the top 6 features gives an F1-score of 0.981, which is a small drawback considering that we are using half of the features. Plus, we see a similar performance using only the top 4 features.
With this example, we can clearly see how feature selection can only simplify the model, but also increase its performance, even if we are working with a simple toy dataset.
Of course, using a different evaluator of the feature importance might lead to different results. I invite you to use another test than the chi squared test, and see for yourself if the resulting plot changes drastically.
Let’s move on to the last method we will implement: Recursive Feature Elimination or RFE.
Recursive Feature Elimination (RFE)
The last method we implement in this article is Recursive Feature Elimination or RFE.
The RFE procedure can be visualized in the figure below.

From the figure above, we see that RFE also requires us to set a number of features. From there, it will gradually remove the least important feature until it reached the the desired number of features.
What is interesting about this feature selection method, is that it relies on the model’s capacity to evaluate the importance of a feature. Therefore, we must use a model that returns either a coefficient or a measure of feature importance.
Here, since we are using a decision tree, the model can actually calculate the importance of a feature.
In a decision tree, the importance of a feature is calculated as the decrease in node impurity multiplied by the probability of reaching that node. This is based on the CART algorithm that runs behind the scenes of a decision tree. You can read more about it here.
Now, let’s test the RFE selection method. We will set the number of input variables to 4, and see how the performance compares to selecting the top 4 features using the chi squared test. That way, we will see which method of evaluating feature importance (chi squared test or feature importance as computed by the decision tree) can choose the best four features for our model.
Implementing RFE is very straightforward using sklearn. First, we define the selector and specify the number of features we want. In this case, we want four. Then, we fit the selector on the training set, which will return us the top 4 features.
from sklearn.feature_selection import RFE
X_train_v3, X_test_v3, y_train_v3, y_test_v3 = X_train.copy(), X_test.copy(), y_train.copy(), y_test.copy()
RFE_selector = RFE(estimator=dt, n_features_to_select=4, step=1)
RFE_selector.fit(X_train_v3, y_train_v3)
We can also see the name of the selected features by accessing the support_ attribute.
X_train_v3.columns[RFE_selector.support_]
Here, we see that the top 4 features are:
- alcalinity_of_ash
- flavanoids
- color_intensity
- proline
Remember that these are the top 4 most important features as evaluated by the decision tree itself.
Now, we can fit the model using only those top 4 features and calculate the F1-score on the test set.
sel_X_train_v3 = RFE_selector.transform(X_train_v3)
sel_X_test_v3 = RFE_selector.transform(X_test_v3)
dt.fit(sel_X_train_v3, y_train_v3)
RFE_preds = dt.predict(sel_X_test_v3)
rfe_f1_score = round(f1_score(y_test_v3, RFE_preds, average='weighted'),3)
print(rfe_f1_score)
Optionally, we can visualize the performance of both models that use only the top 4 features.

Looking at the figure above, we see that the top 4 features as selected by the chi squared test resulted in a better performance.
Now, the take-home message is not that K best feature is a better feature selection method than RFE. The main difference lies in how the importance of the feature is computed. One used the chi squared test, while the other used the feature importance as calculated by the decision tree.
Therefore, we can conclude that, in this case, using the chi squared test is a better way of evaluating the top 4 best features.
Conclusion
In this article, we looked at feature selection, which is a way to reduce the number of features in a model to simplify it and improve its performance.
We explored and implemented three different feature selection methods:
- variance threshold
- K best features
- recursive feature elimination (RFE)
Variance threshold is good to remove features that have 0 variance, as a constant variable is definitely not a good variable. However, setting a variance threshold is hard and quite arbitrary, and I suggest using it along K best features or RFE.
With K best features, we are able to choose how to evaluate the importance of a feature, which also allows us to determine the best method and the best number of features to include in our model.
Finally, RFE is another feature selection method, that relies on the model itself to compute the importance of a feature.
Note that there is no best way of selecting features. It is important to test different feature selection methods and different feature importance evaluation methods to see which one works best for a given problem.
Thank you for reading and I hope learned something useful!
Cheers 🍺
Support me
Enjoying my work? Show your support with Buy me a coffee, a simple way for you to encourage me, and I get to enjoy a cup of coffee! If you feel like it, just click the button below 👇

Stay connected with news and updates!
Join the mailing list to receive the latest articles, course announcements, and VIP invitations!
Don't worry, your information will not be shared.
I don't have the time to spam you and I'll never sell your information to anyone.
